


Next:
Up:
Previous:
Perceptron training rule guaranteed to succeed if
- Training examples are linearly separable
- Sufficiently small learning rate
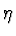
Linear unit training rule uses gradient descent
- Guaranteed to converge to hypothesis with minimum squared error
- Given sufficiently small learning rate
- Even when training data contains noise
- Even when training data not separable by H
