


Next:
Up:
Previous:
- Gradient descent over entire network weight vector
- Easily generalized to arbitrary directed graphs
- Will find a local, not necessarily global error minimum
- In practice, often works well (can run multiple times)
- Often include weight momentum
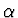
- Minimizes error over training examples
- Will it generalize well to subsequent examples?
- Training can take thousands of iterations
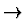 slow!
slow!
- Using network after training is very fast
