DNN Training and Graph Learning at the Edge
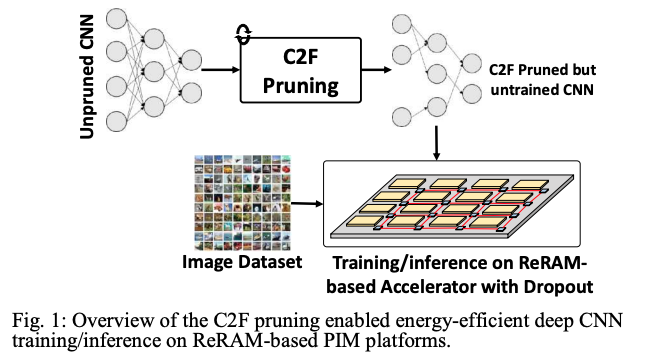
Training machine learning (ML) models at the edge (training on-chip or on embedded systems) can address many pressing challenges, including data privacy/security, increase the accessibility of ML applications to different parts of the world by reducing the dependence on the communication fabric and the cloud infrastructure, and meet the real-time requirements of AR/VR applications. Our research focus is on energy-efficient and high-performance processing-in-memory, architectures, and Algorithm Cross-Layer Software & Hardware Co-Design, with applications in AI, Deep Neural Networks and Graph Processing. The goal of our research is to develop high performance and energy-efficient domain-specific architectures for accelerating Machine Learning training and inferencing tasks on the edge (i.e., on-device learning). For example, we recently proposed a ‘hardware-aware’ compression technique (Fig. 1) for DNNs, which can potentially enable energy-efficient training on the edge [2][4]. Overall, the work seeks to address the energy, latency, security/privacy, concerns associated with today’s existing architectures.
Publications
[1] P. Dhingra, C. Ogbogu, B. Joardar, J. Doppa, P. Pande ‘FARe: Fault-Aware GNN Training on ReRAM-based PIM Accelerators’ to appear in IEEE Design, Automation and Test in Europe (DATE) Conference 2024.
[2] C. Ogbogu et al., “Energy-Efficient ReRAM-Based ML Training via Mixed Pruning and Reconfigurable ADC,” 2023 IEEE/ACM International Symposium on Low Power Electronics and Design (ISLPED), Vienna, Austria, 2023, pp. 1-6, doi: 10.1109/ISLPED58423.2023.10244258.
[3] C. Ogbogu, M. Abernot, C. Delacour, A. Todri-Sanial, S. Pasricha and P. P. Pande, “Energy-Efficient Machine Learning Acceleration: From Technologies to Circuits and Systems” 2023 IEEE/ACM International Symposium on Low Power Electronics and Design (ISLPED), Vienna, Austria, 2023, pp. 1-8, doi: 10.1109/ISLPED58423.2023.10244360.
[4] C. Ogbogu, A. Arka, L. Pfromm, B.Joardar, J. Doppa, K. Chakrabarty, P. Pande, “Accelerating Graph Neural Network Training on ReRAM-based PIM Architectures via Graph and Model Pruning” in IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, Dec. 2022.
[5] C. Ogbogu, A. Arka, B. Joardar, J. Doppa, H. Li, K. Chakrabarty, P. Pande, “Accelerating Large-Scale Graph Neural Network Training on Crossbar Diet,” in IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, vol. 41, no. 11, pp. 3626-3637, Nov. 2022.