Chiplet-based Architecture Design
Processing-in-memory (PIM) is a promising technique to accelerate deep learning (DL) workloads. Emerging DL workloads (e.g., ResNet with 152 layers) consist of millions of parameters, which increase the area and fabrication cost of monolithic PIM accelerators. The fabrication cost challenge can be addressed by 2.5-D systems integrating multiple PIM chiplets connected through a network-on-package (NoP). However, server-scale scenarios simultaneously execute multiple compute-heavy DL workloads, leading to significant interchiplet data volume. State-of-the-art NoP architectures proposed in the literature do not consider the nature of DL workloads. In this article, we propose a novel server scale 2.5-D manycore architecture called SWAP that accounts for the traffic characteristics of DL applications. Comprehensive experimental evaluations with different system sizes as well as diverse emerging DL workloads demonstrate that SWAP achieves significant performance and energy consumption improvements with much lower fabrication cost than state-of-the-art NoP topologies.
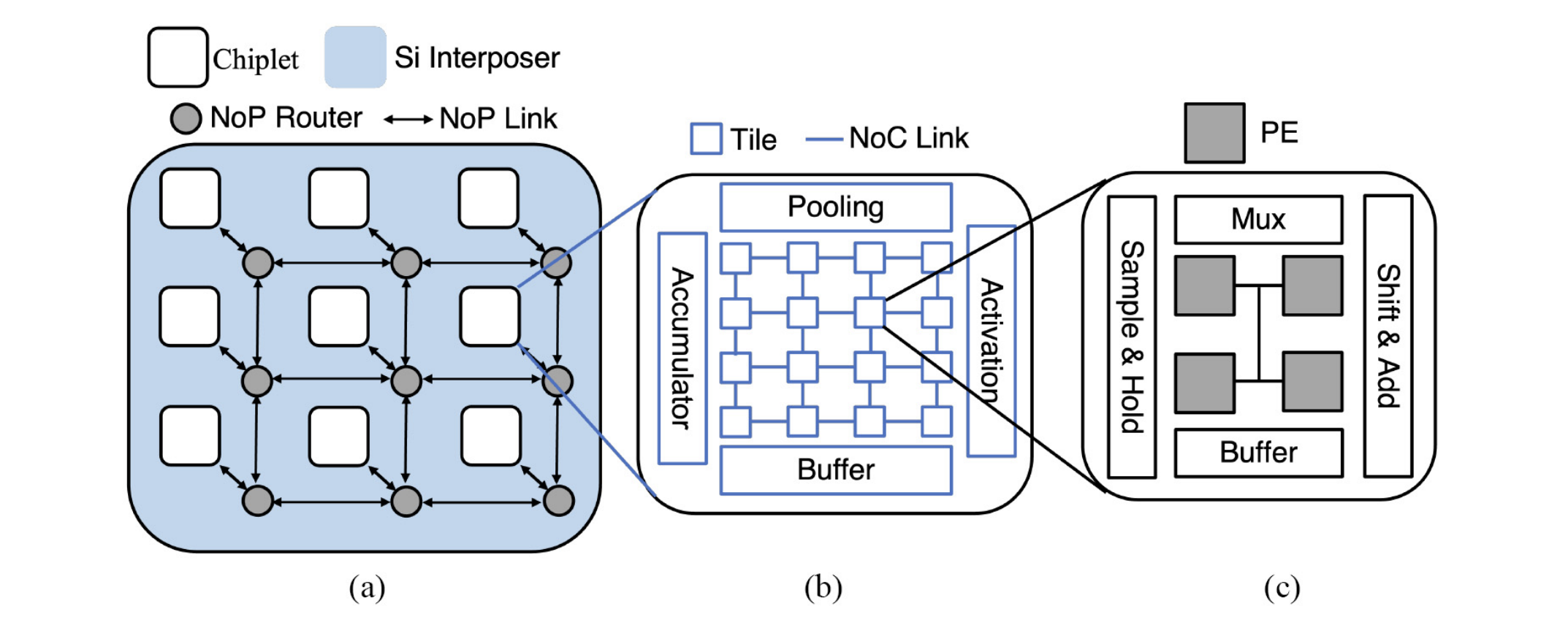
For Datacenter-scale CNN tasks, we have demonstrated a neuromorphic SFC-based architecture called Florets for Chiplets. The research demonstrates significant performance gain, significant reduction in energy consumption, lower fabrication cost, and lower embodied carbon footprint when inferencing datacenter-scale AI workloads. Our work is cost-effective and high-performing, while also aligning with global efforts to combat climate change. We use the concept of Space Filling Curves (SFCs) to the design the network-on-interposer (NoI) for datacenter-scale chiplet systems for concurrent CNN inference tasks. The key idea is to preserve data locality by exploiting the data-flow in deep neural networks. Hence data-flow aware.
We call the architecture “Floret” as the topology can be viewed as a cluster of individual space-filling curves (or petals). We enable redundancy of computing resources in a chiplet-based architecture.

Florets for Chiplets is published in the Hardware/Software Codesign(CODES+ISSS) track and got the ESWEEK best paper award for the year 2023. The conference is a forum bringing together academic research and industrial practice for all aspects related to system-level and hardware/software co-design including system-level design, hardware/software co-design, modeling, analysis, and implementation of modern Embedded Systems, Cyber-Physical Systems (CPS), and Internet-of-Things (IoT).

Articles
-
Florets for Chiplets Talk (Youtube) - Harsh Sharma
-
Accelerating the Future of Electronics: - Harsh Sharma @ Medium
-
Unlocking Pattern Thinking (1.0): A Fundamental Approach to Problem Solving - Harsh Sharma @ Medium
Publications
-
{BEST PAPER AWARD} Harsh Sharma, Lukas Pfromm, Rasit Onur Topaloglu, Janardhan Rao Doppa, Umit Y. Ogras, Ananth Kalyanraman, Partha Pratim Pande.Florets for Chiplets: Data Flow-aware High-Performance and Energy-efficient Network-on-Interposer for CNN Inference Tasks. - ESWEEK Conference 2023. Published in ACM Transactions on Embedded Computing Systems Volume 22, September 2023
-
{BEST PAPER AWARD} Harsh Sharma, Sumit K. Mandal, Jana Doppa, Umit Ogras and Partha Pratim Pande. SWAP: A Server-Scale Communication-Aware Chiplet-Based Manycore PIM Accelerator. - ESWEEK Conference 2022. Published in IEEE TRANSACTIONS ON COMPUTER-AIDED DESIGN OF INTEGRATED CIRCUITS AND SYSTEMS, VOL. 41, NO. 11, NOVEMBER 2022.
-
Harsh Sharma, Sumit K. Mandal, Jana Doppa, Umit Ogras and Partha Pratim Pande. Achieving Datacenter-scale Performance through Chiplet-based Manycore Architectures - Published in 2023 Design, Automation & Test in Europe Conference (DATE 2023) held in Antwerp, Belgium.